首页
PyTorch官网
PyTorch pip安装
PyTorch whl安装
CUDA安装
cuDNN安装
GPU并行训练
PyTorch官方入门
PyTorch API学习
PyTorch Lightning
PyG官方入门
PyTorch精品教程
Tensor维度详解
PyTorch计算图
梯度下降法
PyTorch Adam
梯度装饰器
电子书与软件
AI数学电子书
希腊字母列表
AI作图工具
LaTex入门教程
LaTex常用命令
LaTex在线编辑器
关于网站
分类
深度强化学习技术分享
下的文章
PPO 算法代码复现:从理论到 PyTorch 实战
撰写于:
2026-05-26
浏览:37 次 分类:
深度强化学习技术分享
摘要近端策略优化(Proximal Policy Optimization, PPO)是深度强化学习领域最主流的算法之一,其在机器人控制、大语言模型对齐等场景中应用广泛。然而,PPO 的实现细节繁多,超参数敏感,初学者常遭遇“代码跑通了但模型不收敛”的困境。本文提供一份完整的 PPO PyTorch 复现指南,从 Actor-Critic 网络设计[...]
Proximal Policy Optimization (PPO) 算法的全面理解
撰写于:
2025-12-15
浏览:619 次 分类:
深度强化学习技术分享
提示:本文更新于2025年12月17日在线学习和离线学习介绍在强化学习中,在线学习和离线学习代表了两种不同的数据使用范式。在线学习要求智能体通过与环境实时交互来收集数据,并立即用这些新数据更新策略。这种方法使智能体能够持续探索最新状态,但其“边交互边学习”的特性也容易导致策略更新不稳定——当新策略偏离旧策略过多时,可能引发性能的断崖式下降。以PPO[...]
基于环境建模的强化学习方法
撰写于:
2024-09-06
浏览:1109 次 分类:
深度强化学习技术分享
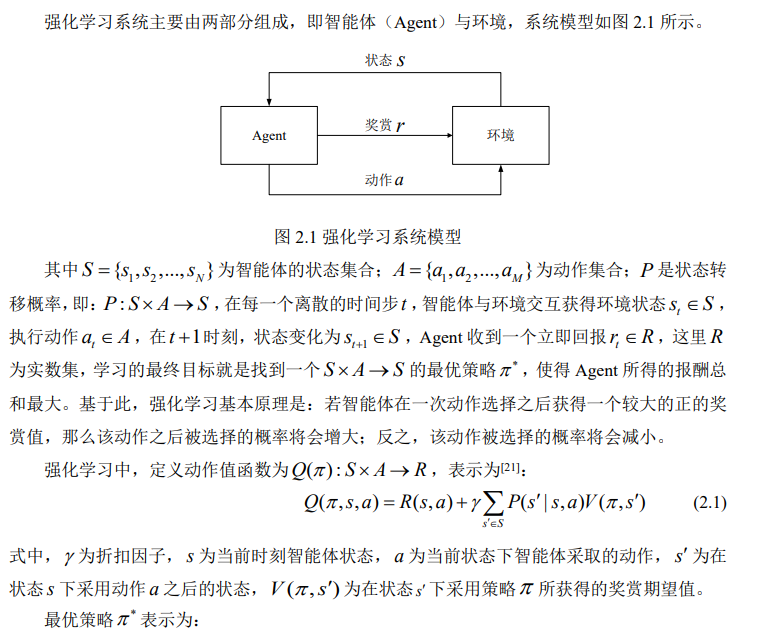
强化学习的核心思想是通过Agent与环境的不断交互,以最大化累计回报为目标来选择合理的行动,这与人类智能中经验知识获取和决策过程不谋而合。特别是近年来深度强化学习在以AlphaGo、AlphaZero、AlphaStar等为代表的机器智能领域的突破,进一步展现了强化学习在解决复杂决策问题的能力,成为人工智能研究领域的热点。当前强化学习主要研究的方法[...]
2024年为简历添份彩:无人机实战项目
撰写于:
2024-08-21
浏览:1201 次 分类:
深度强化学习技术分享
提示:本社群名额有限,目前计划控制为100人,截止2024年8月24日,当前已经有35人加入。1、求职简历存在的问题本站自上线以来,站长以及广大热心网友无偿分享了很多AI相关的电子书,获得了很多AI初学者的认可!同时,也有不少人私下咨询站长关于面试的问题。站长发现很多人的简历写得很空洞,没有亮点,缺少动手项目。技术本来是要用的,而不是记的,只有动起[...]
Pop-Art算法详细介绍
撰写于:
2024-07-14
浏览:1508 次 分类:
深度强化学习技术分享
Pop与Art分别表示Preserving Outputs Percisely以及Adaptive Rescaling Target, 即在保障已历经样本输出不变的前提下自适应缩放target值的算法。这个算法来自文献:《Multi-task Deep Reinforcement Learning with popart》。PopArt这个算法本来[...]
强化学习基本原理
撰写于:
2023-07-01
浏览:1475 次 分类:
深度强化学习技术分享
Q-learning 算法介绍
撰写于:
2023-06-29
浏览:1496 次 分类:
深度强化学习技术分享
Q-Learning是强化学习中的最基础算法,它基于Q-Table来实现。这个表格的每一行都代表着一个状态(state),每一行的每一列都代表着一个动作(action),而每个值就代表着如果在该state下采取该action所能获取的最大的未来期望奖励。通过Q-Table就可以找到每个状态下的最优行为,进而通过找到所有的最优action来最终得到最[...]
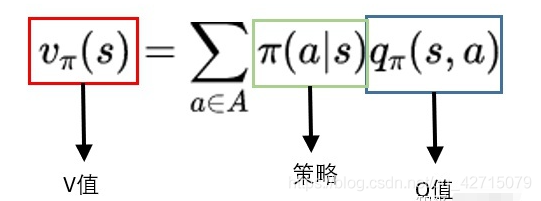
深刻理解强化学习中的Q值和V值
撰写于:
2023-06-29
浏览:1668 次 分类:
深度强化学习技术分享
在马尔可夫决策过程中,当智能体从一个状态S,选择动作A,会进入另外一个状态S'。同时,也会给智能体奖励R。 奖励既有正,也有负,正代表我们鼓励智能体在这个状态下继续这么做,负得话代表我们并不希望智能体这么做。 在强化学习中,我们会用奖励R作为智能体学习的引导,期望智能体获得尽可能多的奖励。需要注意的是:很多时候,我们并不能单纯通过R来衡量一个动作的[...]
protobuf 版本问题:Downgrade the protobuf package to 3.20.x or lower.
撰写于:
2023-05-22
浏览:6498 次 分类:
深度强化学习技术分享
1、Protobuf 简介Protocol Buffers(简称 Protobuf),是Google公司开发的一种数据描述语言,类似于XML能够将结构化数据序列化,可用于数据存储、数据交换、通信协议等方面。相比于它的前辈XML、Json,它的体量更小,解析速度更快,所以在业内获得了广泛的应用。在多智能体强化学习过程中,由于多个Agent位于不同的节[...]
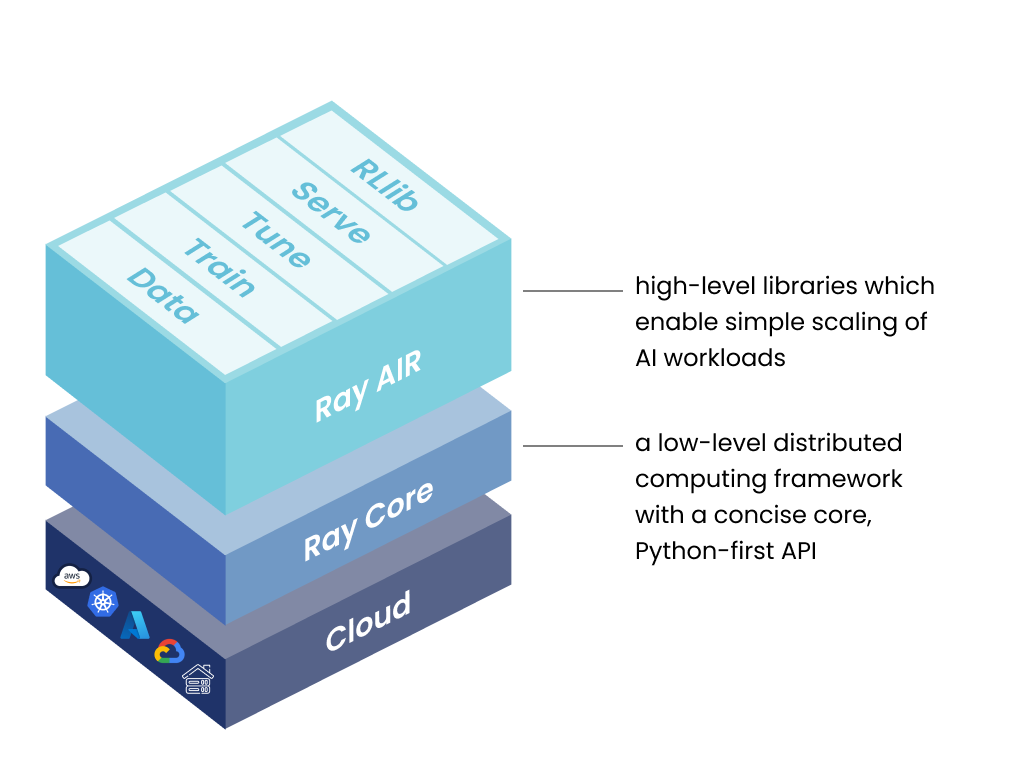
分布式框架Ray详细介绍
撰写于:
2023-05-21
浏览:2646 次 分类:
深度强化学习技术分享
Ray简介Ray是一个开源的人工智能分布式框架,它的目标是让开发者仅需添加数行代码就能轻松转为适合于计算机集群运行的高性能分布式应用。今天的深度学习越来越需要计算资源,像笔记本电脑这样的单节点开发环境无法扩展以满足算力需求,Ray是将Python和AI应用程序从笔记本电脑扩展到集群的统一方法。使用Ray,您可以将相同的代码从笔记本电脑无缝扩展到集群[...]
强化学习中REINFORCE算法详细介绍
撰写于:
2023-05-20
浏览:2076 次 分类:
深度强化学习技术分享
REINFORCE介绍强化学习中的策略优化主要有两类:基于价值的方法和基于策略的方法(当然两者的结合产生了 Actor-Critic 等算法)。基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。基于价值的方法主要有DQN,而基于策略的方法有REINFORC[...]
value-based和policy-based的区别是什么?
撰写于:
2023-05-20
浏览:2890 次 分类:
深度强化学习技术分享
强化学习中的策略优化主要有两类:基于value价值的方法和基于policy策略的方法(当然两者的结合产生了 Actor-Critic 等算法)。基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。value-based方法是先通过计算出值函数,然后再求策略;[...]
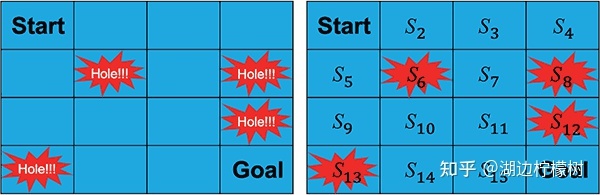
马尔可夫决策过程(MDP)是什么?
撰写于:
2023-05-19
浏览:1385 次 分类:
深度强化学习技术分享
马尔可夫决策过程简介马尔可夫决策过程(Markov Decision Processes,MDP)是对强化学习中环境的形式化的描述,或者说是对于智能体所处的环境的一个建模。在强化学习中,几乎所有的问题都可以形式化地表示为一个马尔可夫决策过程。本文以Frozen Lake游戏为例,介绍一下马尔可夫决策过程。Frozen Lake 游戏介绍Frozen[...]
env.unwrapped 的作用
撰写于:
2023-05-18
浏览:2105 次 分类:
深度强化学习技术分享
当我们使用gym创建环境的时候:env = gym.make('CartPole-v0')返回的env其实并非CartPole类本身,而是一个经过包装的环境。包装的过程可以看这里:def make(self, path, **kwargs): spec = self.spec(path) env = spec.m[...]
MuJoCo 简介
撰写于:
2023-03-18
浏览:3411 次 分类:
深度强化学习技术分享
MuJoCo 简介MuJoCo全称为Multi-Joint dynamics with Contact,主要由华盛顿大学的Emo Todorov教授开发,应用于最优控制、状态估计、系统辨识等领域,在机器人动态多点接触的应用场合(如多指灵巧手操作)有明显优势。MuJoCo 现状介绍MuJoCo最初由华盛顿大学运动控制实验室主任、神经科学家Emo To[...]
1
2
关注公众号,感悟技术与人生
飞燕网
一个踏实、严谨的网站!
专注于PyTorch、强化学习和大模型技术
分类
默认分类
PyTorch 电子书
Python 电子书
推荐系统电子书
计算机视觉电子书
机器学习电子书
强化学习电子书
PyTorch 教程
AI数学电子书
数据结构与算法电子书
人工智能实习与内推
网站公告
图神经网络电子书
飞燕AI收徒
深度强化学习技术分享
科研论文
大模型电子书
技术与人生杂谈
考研分享
LangChain电子资源
DeepSeek技术研究
最新文章
Transformer教程网成立了...
《AI量化之道:DeepSeek+Python让量化交易插上翅膀》高清完整...
2026年具身智能最热门的十大技术
PPO 算法代码复现:从理论到 PyTorch 实战
《Python FastAPI构建数据科学应用》高清完整PDF版下载
《玩转Python FastAPI》高清完整PDF版下载
《DeepSeek开发实战》高清完整PDF版下载
《图解DeepSeek技术》高清完整PDF版下载
《LangChain 1.0智能体开发实战》高清完整PDF版下载
《LangChain大模型应用开发》高清完整PDF版下载
《LangChain核心技术与LLM项目实践》高清完整PDF版下载
《LangChain实战:从原型到生产,动手打造 LLM 应用》高清完整P...
《LangChain与LangGraph实战》高清完整PDF版下载
《改变世界的12个算法》高清完整PDF版下载
2026年社群的发展规划
热门文章
《 百面深度学习》高清完整PDF版 下载
网站公告:2026年5月网站资源下载公告
《深度学习推荐系统》全彩版 高清完整PDF版 下载
《Python深度学习:基于PyTorch》中文版 高清完整PDF版 下载
技术交流群-成员昵称-参考列表
《机器学习的数学》高清完整PDF版 下载
《优美的数学思维(原书第2版)》高清完整PDF版 下载
Keras怎么读?解读Keras英文发音
最新评论
kk
:
已经加了微信呢
david
:
怎么下载
czs
:
通俗易懂的经典书籍
admin
:
可以加微信私信我。
佚名
:
你好,在哪下载电子版[...]
Nitrite
:
好
瑾年
:
非常好的书
阿瑶
:
求书
xxxx
:
谢谢
安全科学家
:
请赐教,谢谢
友情链接