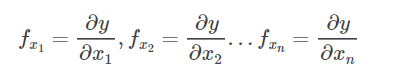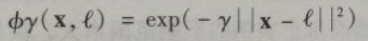首页
PyTorch官网
PyTorch pip安装
PyTorch whl安装
CUDA安装
cuDNN安装
GPU并行训练
PyTorch官方入门
PyTorch API学习
PyTorch Lightning
PyG官方入门
PyTorch精品教程
Tensor维度详解
PyTorch计算图
梯度下降法
PyTorch Adam
梯度装饰器
电子书与软件
AI数学电子书
希腊字母列表
AI作图工具
LaTex入门教程
LaTex常用命令
LaTex在线编辑器
关于网站
2019年6月
史上最全:梯度的物理意义
撰写于:
2019-06-20
浏览:9872 次 分类:
AI数学电子书
备注:本文修改时间为2021年5月27日大家好,我是飞燕网的站长,本文给大家说一下梯度以及梯度的物理意义吧。对于“梯度”这个东西,很多初学者搞不清楚,就连知乎上的大V,也是独乐乐不能与众乐乐,洋洋散散说了半天,读者也是一头雾水。之所以大家对“梯度”一头雾水,这是因为大家没有一个明确的理解路线,站长对梯度的理解路线为:导数->偏导数->方[...]
趣谈数学之六:认识的误区
撰写于:
2019-06-18
浏览:1591 次 分类:
AI数学电子书
数学,不仅仅是去记公式,更要用心的去感受它,而且尽量的去多学,去深挖,这可能会花费很多的时间,导致有人会害怕浪费时间,毕竟很多人是面临着找工作的压力。多学一点无用的知识顶多算是多了点噪声,害怕多学而浪费时间,害怕深挖而浪费时间,这个已经属于观念级别的问题,已经达到激活函数层次,因为人的每个观念本质上就是人工智能领域中的激活函数。在这个层次如果有偏差[...]
趣谈数学之五:数据结构和算法,其实是数学的分支
撰写于:
2019-06-15
浏览:1798 次 分类:
AI数学电子书
虽然都是数学,线性代数和高数等其他数学分支,需要对知识的内涵加以深度的理解和思考,而数据结构和算法,更侧重于外形方面的认识。数据结构和算法,是我们很多人的弱项,究其原因,这也不能全怪于我们的学习方法有问题,而在于我们传统教育的土壤,因为我们中国人讲究含蓄,传统教育以分析内涵为主,而数据结构和算法这门学科,却以外形为主,例如链表,双向链表,树,图等。[...]
简明机器学习教程13:评价模型
撰写于:
2019-06-13
浏览:1584 次 分类:
机器学习电子书
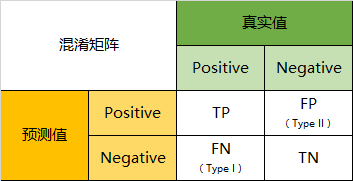
建好模型之后,必须对它进行评价,我们经常会使用一些评价指标来比较模型的预测准确度。常用的评价指标有:预测准确率,混淆矩阵,均方根误差等。1、分类指标1.1、预测准确率简单的说,就是正确的预测所占的比例。虽然它很简单容易理解,但是我们无法通过它得知预测误差是如何产生的。1.2、混淆矩阵混淆矩阵可以进一步了解预测模型的优缺点。通过样本的采集,我们能够直[...]
简明机器学习教程12:识别关联规则的常用指标
撰写于:
2019-06-12
浏览:1615 次 分类:
机器学习电子书
常用指标有3个:(1){X}的支持度表示X项出现的频率,可以表示为P(X)(2){X→Y}的置信度表示当X项出现时Y项同时出现的频率,可以表示为:P(XY)/P(X)(3){X→Y}的提升度表示X项和Y项一同出现的频率,并且考虑每项各自出现的频率,可以表示为:P(XY)/P(X)P(Y)。公式看起来很容易理解,但是在实际问题中,我们常用被项集这个概[...]
趣谈数学之四:田忌赛马永流传
撰写于:
2019-06-12
浏览:1496 次 分类:
AI数学电子书
学人工智能的人群分两类,一种是将数学当做人工智能的工具,另一类人是将人工智能当数学的工具。首先要扪心自问一下,看看自己属于哪类人?然后反思一下,看看是否正确。田忌赛马的故事,流传至今,说明了一个道理:调整一下顺序,格局完全不一样。上面的两类人的认知上的区别,无非就是顺序上的差异。
简明机器学习教程11:主成分与标准化
撰写于:
2019-06-11
浏览:1396 次 分类:
机器学习电子书
主成分可以用已有的一个或多个变量表示。 比如,可以使用生素C这个变量来区分不同的食物。因为蔬菜含维生素C而肉类普遍缺乏,所以可以通过维生素C这个变量区分蔬菜和肉类,但是无法进步区分不同的肉类。为了进一步区分不同的肉类,可以选择把脂肪含量作为第2个变量,因为肉类含有脂肪,而大部分蔬菜则不然。由于脂肪和维生素C的计量单位不同,因此在组合之前,必须先对它[...]
简明机器学习教程10:K均值聚类的局限性
撰写于:
2019-06-10
浏览:1754 次 分类:
机器学习电子书
尽管K均值聚类方法很有用,但是它有一定的局限:(1)每个数据点只能属于一个群组。然而,数据点可能恰好位于两个群组中间,无法通过k均值聚类方法确定它应该属于哪个群组(2)群组被假定是正圆形的。查找距离某个群组中心点最近的数据点,这一迭代过程类似于缩小群组的半径,因此最终得到的群组在形状上类似于正圆形。假设群组的实际形状是椭圆形,那么在应用k均值聚类方[...]
简明机器学习教程9:超参数和参数
撰写于:
2019-06-09
浏览:1522 次 分类:
机器学习电子书
机器学习一般包含两类参数:超参数和参数。超参数的数目通常不多,在10以内。参数的数目可能很多,如卷积神经网络中有近千万个参数(权重)。曲线拟合中,方程的次数就是超参数,多项式的系数就是参数。这两种参数的调参方式不同,超参数取值一般是人工设定的,参数值是根据参数优化算法自动寻优的。超参数的取值对模型泛化性能有重大的影响,验证集就是用来决定最优超参数取值的。
趣谈数学之三:马尔科夫链与座右铭
撰写于:
2019-06-09
浏览:1601 次 分类:
AI数学电子书
人的思维也是一种物质,只要它是物质必然遵循着某种运动规律。读研期间学过《随机过程》,知道有个马尔科夫链,记得当时在大的阶梯教室上课,学习的效果也不是很好,反正已经不记得了。过了多年,经过生活的阅历,最终发现马尔科夫链还有非常重要的现实意义。在改变自己的过程中,人们喜欢设立一个座右铭,每天读一读,以提醒自我。这个行为有什么数学依据呢?我们知道马尔科夫[...]
简明机器学习教程8:图像的特征:计算机“看到”的图像是什么?
撰写于:
2019-06-08
浏览:1529 次 分类:
机器学习电子书
计算机“看”不到图像的内容,对它而言,图像是巨大的数值,即数值矩阵,矩阵元素表示像素的颜色信息。例如,某幅图像分群率为1280 x 720,表示图像有1280 x 720个像素点,则存储为1280 x 720的矩阵。对于彩色图像,每个像素点有红、绿、蓝( RGB)3个颜色的通道值,每个值在0(黑)到255(白)之间。对于灰度图像,每个像素点有亮度1[...]
简明机器学习教程7:特征缩放
撰写于:
2019-06-07
浏览:1422 次 分类:
机器学习电子书
如果输人的数值属性具有非常大的比例差异,往往导致机器学习算法的性能表现不佳,当然也有极少数特例。案例中的房屋数据就是这样:房间总数的范围从6到39 320,而收入中位数的范围是0到15。注意,目标值通常不需要缩放。同比例缩放所有属性,常用的两种方法是:最小-最大缩放和标准化。最小-最大缩放,又叫作归一化,很简单:将值重新缩放使其最终范围归于0到1之[...]
趣谈数学之二:伟大的正态分布,人人都应该深刻认识
撰写于:
2019-06-06
浏览:1756 次 分类:
AI数学电子书
自然界的物体运动都遵循牛顿三大定律,同样道理,人的思维也是一种物质,只要它是物质必然遵循着某种运动规律:任何人,做任何事情,70%的时间和精力都是用来试错的,这些付出并不能带来成功,而真正在正确的方向上努力的时间和精力占比不过30%。我之所以没有采用80%和20%的数字形式,而是为了避免与二八定理相混淆。因为上述规律的发现来自于:正态分布。世人公认[...]
简明机器学习教程6:相似特征
撰写于:
2019-06-06
浏览:1457 次 分类:
机器学习电子书
解决非线性问题的另种技术是添加相似特征。这些特征经过相似函数计算得出,相似函数可以测量每个实例与一个特定地标之间的相似度。以前面提到过的一维数据集为例,在x=-2和x=1处添加两个地标。接下来,我们采用高斯径向基函数(RBF) 作为相似函数,y=0.3 高斯RBF这是一个从0 (离地标差得非常远)到1 (跟地标-样)变化的钟形函数。现在我们准备计算[...]
简明机器学习教程5:多项式特征
撰写于:
2019-06-05
浏览:1410 次 分类:
机器学习电子书
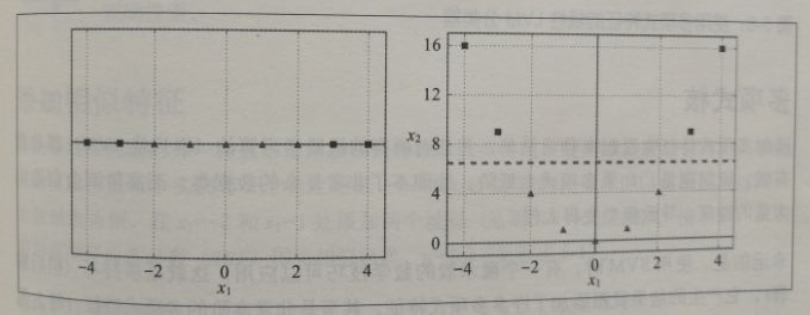
处理非线性数据集的方法之是添加更多特征, 比如多项式特征,某些情况下,这可能导致数据集变得线性可分离。下图是一个简单的数据集,只有一个特征x,可以看出,数据集线性不可分,但是如果添加第二个特征x2=(x1)2,生成的2D数据集则完全线性可分离。 一个简单的方法就是将每个特征的幕次方添加为一个新特征,然后在这个拓展过的特征集上训练线性模型。一般情况下[...]
1
2
关注公众号,了解站长最新动态
分类
默认分类
PyTorch 电子书
Python 电子书
推荐系统电子书
计算机视觉电子书
机器学习电子书
强化学习电子书
PyTorch 教程
AI数学电子书
数据结构与算法电子书
人工智能实习与内推
网站公告
图神经网络电子书
飞燕AI训练营
多智能体与无人机
科研论文
大模型电子书
创业杂谈
PyTorch GPU 并行训练
PyTorch Lightning 使用介绍
睡前数学APP
最新文章
L1范数倾向于产生稀疏解
L1范数倾向于产生稀疏解的举例说明
torch.max的详细介绍
L1范数的作用是什么?
欧几里得范数是什么?它有什么用?
向量的范式是什么?它有什么用?
torch.norm的详细介绍与使用举例
torch.frombuffer的详细介绍
torch.tensor()和torch.as_tensor()的区别是什么?
torch.asarray和torch.as_tensor的区别是什么?
torch.asarray的详细介绍
torch.polar的详细介绍
torch.heaviside的详细介绍
torch.logspace的详细介绍
torch.linspace的详细介绍
热门文章
《 百面深度学习》高清完整PDF版 下载
《深度学习推荐系统》全彩版 高清完整PDF版 下载
《Python深度学习:基于PyTorch》中文版 高清完整PDF版 下载
技术交流群-成员昵称-参考列表
2025年2月网站资源下载公告
《机器学习的数学》高清完整PDF版 下载
《优美的数学思维(原书第2版)》高清完整PDF版 下载
Keras怎么读?解读Keras英文发音
最新评论
瑾年
:
非常好的书
阿瑶
:
求书
xxxx
:
谢谢
安全科学家
:
请赐教,谢谢
matt
:
非常值得推荐
晒衣你
:
好书
半缘君
:
个人学习用,谢谢支持
xiaobai
:
大佬,可以麻烦您发我[...]
bodong
:
感谢分享
Ruozi
:
非常好的书
友情链接